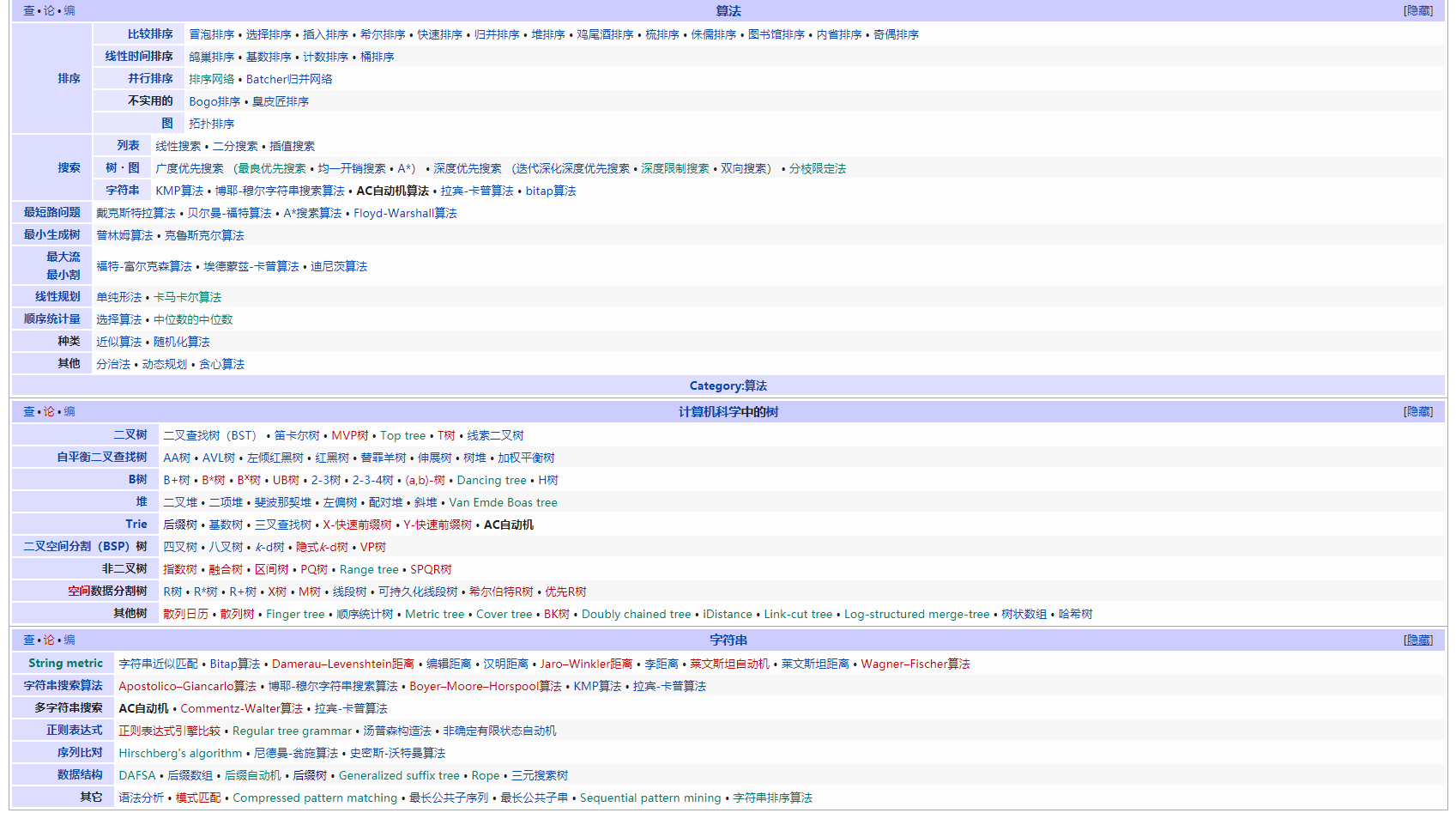
树型结构数据与应用
算法类
- Aho-Corasick算法
1
1. 进行全文匹配关键字,比如:敏感词匹配。需要预处理数据
- Boyer- Moore算法
1
1. 字符串查找。需要预处理数据
- KMP算法
1
1. 字符串查找。需要预处理数据
- Manacher算法
1
1. 中心扩展,计算最长回文子串。需要辅助空间
树(字符串类)
编码类
- 霍夫曼编码(哈夫曼树)
1
1. 压缩数据存储,需要辅助空间。
树遍历构造
- 二叉树遍历:前序,中序,后序,Morris
- 树构造:状态机
知识界限
- 个人理解,以下内容在于多多学习,学习其中思想理念,能够在使用中想到有什么解决方案。