背景
- 需要对系统进行流程性测试,查找系统瓶颈点所在,当大流量来临能有效应对。现将优化处理方法进行梳理总结,供大家参考学习
系统参数
| 系统服务名 | 服务器数量 | CPU(核) | 内存(G) |
|---|---|---|---|
| nginx | 2 | 4 | 8 |
| gateway | 4 | 8 | 16 |
| course(不同服务器类型) | 2 | 2 | 4 |
| course(不同服务器类型) | 2 | 8 | 64 |
| user | 2 | 2 | 4 |
| login | 2 | 2 | 4 |
| 数据库1 | 1 | 8 | 16 |
| 数据库2 | 1 | 8 | 16 |
| redis | 1 | 2 | 2 |
- 服务器说明:在测试中有直连进行测试,实际测试某一个服务中,未全部使用服务器,会根据测试内容临时下线机器,具体方案会在后续说到。
- 启动参数中:gateway使用内存配置为4g。 其他应用服务启动参数内存为2g
压测优化点内容
gateway优化项
网关核心功能
- 路由转发
- 流量计算/限流
- 统一登录验证
spring cloud gateway文档:https://docs.spring.io/spring-cloud-gateway/docs/2.2.6.RELEASE/reference/html/#gateway-starter
-Dreactor.netty.ioWorkerCount=64
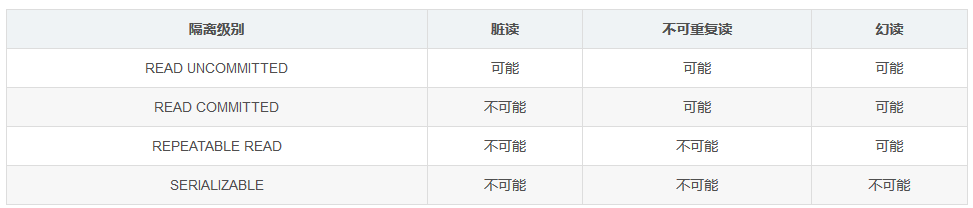
问题1:线程数量设置过小。
- 被压测接口:返回当前系统时间。接口响应平均响应时间在1毫秒不到
- 压测方法:直连tomcat压测,和通过gateway在连接对比压测
- 压测QPS:tomcat直连:3W+ 。 gateway链接:1500+
- 说明:gateway有进行redis的登录验证操作,耗时在2、3毫秒左右,redis的瓶颈在1W左右
- 压测过程中,对比后发现gateway服务器的cpu利用率很低,对比发现属于redis验证阻塞了主线程,导致请求无法及时转发。
- gateway使用reactor netty进行作为转发框架。默认设置为cpu数量同等线程数,但只适合cpu密集型任务,对于路由转发任务需要调高线程数量,以便于提高cpu利用率
参考文章:https://blog.csdn.net/trecn001/article/details/107286396
问题2:登录验证redis存在大key
- 被压测接口:同问题1一致
- 压测方法:同问题1一致
- 压测QPS:同问题1一致
- 说明:同问题1一致
- 经过解决问题1后,QPS依然维持在1W左右,通过计算,用户登录后存储在redis中字节数为1388个字节,redis带宽为128Mbit/s。换算后redis的带宽瓶颈为QPS:1W+。去掉中间程序因素,只能维持在1w左右
- 追踪程序后,用户登录使用的为jwt验证。会将用户所有数据进行加密存储为accessToken和一个refreshToken。
参考文章:https://www.cnblogs.com/ruoruchujian/p/11271285.html - redis存储信息包含:用户id,用户类型,accessToken,refreshToken,deviceId,jti。同时:根据jwt的规则accessToken加密串已经包含了所有的信息,所以不需要在单独存储。同时查看目前系统登录逻辑refreshToken暂时并没有使用,只是用于一个扩展项。
- 对登录用户信息进行优化,redis不在存储refreshToken,同时对加密token进行字段缩减。只放入userId,deviceId必要字段,加密串大大减少。缩减后剩余388个字节。redis带宽可同步增长3~4倍
应用服务优化项
-
1
2
31. https://www.shuzhiduo.com/A/rV57PbN9dP/
2. 由于actuator会注入很多*号的url。这时候程序使用PathVariable ,会造成很多次的无效匹配
3. 解决:actuator声明一些需要使用的端点,不要使用*号进行 -
1
21. redis带宽不足
2. 程序的并发高,同时用户存储了所有数据,占用大量带宽 应用服务tomcat连接数配置,此项不作说明,需要根据业务系统来定
1
2
3
4server.tomcat.max-threads=300 // springboot默认是200
server.tomcat.accept-count=200 // springboot默认是100
server.tomcat.max-connections=8192 // springboot默认是8192 . 1024*8。
server.tomcat.min-spare-threads=50 // springboot默认是10hystrix使用信号量配置减少CPU上下文切换,此项不作说明,需要根据业务系统来定
1
21. 参考文章:https://blog.csdn.net/dap769815768/article/details/94630276
2. 系统使用了okhttp,本身有配置相应线程池,不需要在使用hystrix进行线程池。以减少cpu争用
优化总结
- 在分布式系统中,需要定位问题点,问题点对应了才能进行解决。上面解决方案非常简单,但难点是定位到各个问题点。同时有可能是多不同问题点叠加产生瓶颈。
- 定位问题中需要进行分解目标点,参考附录大致图中。以下是定位gateway网关的思路。其他接口也可以参照以下思路。使用排除法一步步测试
- 系统经过第一次的压测,将应用服务进行了优化。随后进行第二轮压测,定位至网关redis瓶颈和线程数。定位过程如下
- 在前面压测中,由于应用服务存在瓶颈点,一直未打满gateway,导致无法压测出gateway有瓶颈。本次进行全流程的压测,其中有一个响应在几毫秒内的接口。对比tomcat和网关后发现有巨大差异。
- 压测中需要进行一步步排除差异,第一步:先进行了tomcat压测,排除nginx和gateway,第二步:直连其中一台gateway进行压测,排除nginx,第三步:外网域名压测。
- 结果对比后第二步有巨大差异,而且波动很大。第三步由于nginx有2台,gateway有4台。在物理设备中有增加,但同时也同第一步的结果差异较大
- 通过第二步对比tomcat和经过网关在转发的QPS数后,准备了一个不进行登录验证空接口进行测试(下文该接口记录为A),同时网关有进行登录验证,在准备一个需要登录验证的空接口(下文该接口记录为B)。
- 直接进行tomcat压测,确定应用服务是否存在瓶颈点。对tomcat链接瓶颈疑问直连进行压测。确定tomcat参数正常,不存在相应瓶颈
- 进行第二步操作细化,先使用了A接口进行压测。对比发现QPS相差较小,由于经过网关一层有相比较有下降,稍QPS少一点为正常现象。
- 确定了A接口不存在问题。这时候在使用B接口进行测试,运行效果相差特别大。QPS有10的倍数下降。这时候可以确定为网关登录验证出现问题
- 当前问题进行了细化,网关的登录验证产生瓶颈。这时候定位出2个问题。
- 首先查看了redis瓶颈,通过监控发现redis没有瓶颈,带宽使用量也不高,那么就确定为redis的客户端也就是gateway存在其他瓶颈。
- 首先对gateway的redis连接数进行优化,调高参数,进行再次压测。但调高参数发现并没有效果,同时调高的参数并没有被使用上。在细化后瓶颈点不在redis连接获取数据上
- 对gateway的流程进行梳理,查看开启的线程数量为8个。同时经过跟踪后,redis的操作是在主线程进行。主线程数量不足导致的并发数无法提高
- 提高主线程并发数量,QPS响应开始以倍数提高。最终测试通过
- 系统经过第一次的压测,将应用服务进行了优化。随后进行第二轮压测,定位至网关redis瓶颈和线程数。定位过程如下